|
OpenCV
3.1.0-dev
Open Source Computer Vision
|
|
OpenCV
3.1.0-dev
Open Source Computer Vision
|
We have multiple ways to acquire digital images from the real world: digital cameras, scanners, computed tomography, and magnetic resonance imaging to name a few. In every case what we (humans) see are images. However, when transforming this to our digital devices what we record are numerical values for each of the points of the image.

For example in the above image you can see that the mirror of the car is nothing more than a matrix containing all the intensity values of the pixel points. How we get and store the pixels values may vary according to our needs, but in the end all images inside a computer world may be reduced to numerical matrices and other information describing the matrix itself. OpenCV is a computer vision library whose main focus is to process and manipulate this information. Therefore, the first thing you need to be familiar with is how OpenCV stores and handles images.
OpenCV has been around since 2001. In those days the library was built around a C interface and to store the image in the memory they used a C structure called IplImage. This is the one you'll see in most of the older tutorials and educational materials. The problem with this is that it brings to the table all the minuses of the C language. The biggest issue is the manual memory management. It builds on the assumption that the user is responsible for taking care of memory allocation and deallocation. While this is not a problem with smaller programs, once your code base grows it will be more of a struggle to handle all this rather than focusing on solving your development goal.
Luckily C++ came around and introduced the concept of classes making easier for the user through automatic memory management (more or less). The good news is that C++ is fully compatible with C so no compatibility issues can arise from making the change. Therefore, OpenCV 2.0 introduced a new C++ interface which offered a new way of doing things which means you do not need to fiddle with memory management, making your code concise (less to write, to achieve more). The main downside of the C++ interface is that many embedded development systems at the moment support only C. Therefore, unless you are targeting embedded platforms, there's no point to using the old methods (unless you're a masochist programmer and you're asking for trouble).
The first thing you need to know about Mat is that you no longer need to manually allocate its memory and release it as soon as you do not need it. While doing this is still a possibility, most of the OpenCV functions will allocate its output data automatically. As a nice bonus if you pass on an already existing Mat object, which has already allocated the required space for the matrix, this will be reused. In other words we use at all times only as much memory as we need to perform the task.
Mat is basically a class with two data parts: the matrix header (containing information such as the size of the matrix, the method used for storing, at which address is the matrix stored, and so on) and a pointer to the matrix containing the pixel values (taking any dimensionality depending on the method chosen for storing) . The matrix header size is constant, however the size of the matrix itself may vary from image to image and usually is larger by orders of magnitude.
OpenCV is an image processing library. It contains a large collection of image processing functions. To solve a computational challenge, most of the time you will end up using multiple functions of the library. Because of this, passing images to functions is a common practice. We should not forget that we are talking about image processing algorithms, which tend to be quite computational heavy. The last thing we want to do is further decrease the speed of your program by making unnecessary copies of potentially large images.
To tackle this issue OpenCV uses a reference counting system. The idea is that each Mat object has its own header, however the matrix may be shared between two instance of them by having their matrix pointers point to the same address. Moreover, the copy operators will only copy the headers and the pointer to the large matrix, not the data itself.
All the above objects, in the end, point to the same single data matrix. Their headers are different, however, and making a modification using any of them will affect all the other ones as well. In practice the different objects just provide different access method to the same underlying data. Nevertheless, their header parts are different. The real interesting part is that you can create headers which refer to only a subsection of the full data. For example, to create a region of interest (ROI) in an image you just create a new header with the new boundaries:
Now you may ask if the matrix itself may belong to multiple Mat objects who takes responsibility for cleaning it up when it's no longer needed. The short answer is: the last object that used it. This is handled by using a reference counting mechanism. Whenever somebody copies a header of a Mat object, a counter is increased for the matrix. Whenever a header is cleaned this counter is decreased. When the counter reaches zero the matrix too is freed. Sometimes you will want to copy the matrix itself too, so OpenCV provides the cv::Mat::clone() and cv::Mat::copyTo() functions.
Now modifying F or G will not affect the matrix pointed by the Mat header. What you need to remember from all this is that:
This is about how you store the pixel values. You can select the color space and the data type used. The color space refers to how we combine color components in order to code a given color. The simplest one is the gray scale where the colors at our disposal are black and white. The combination of these allows us to create many shades of gray.
For colorful ways we have a lot more methods to choose from. Each of them breaks it down to three or four basic components and we can use the combination of these to create the others. The most popular one is RGB, mainly because this is also how our eye builds up colors. Its base colors are red, green and blue. To code the transparency of a color sometimes a fourth element: alpha (A) is added.
There are, however, many other color systems each with their own advantages:
Each of the building components has their own valid domains. This leads to the data type used. How we store a component defines the control we have over its domain. The smallest data type possible is char, which means one byte or 8 bits. This may be unsigned (so can store values from 0 to 255) or signed (values from -127 to +127). Although in case of three components this already gives 16 million possible colors to represent (like in case of RGB) we may acquire an even finer control by using the float (4 byte = 32 bit) or double (8 byte = 64 bit) data types for each component. Nevertheless, remember that increasing the size of a component also increases the size of the whole picture in the memory.
In the Load, Modify, and Save an Image tutorial you have already learned how to write a matrix to an image file by using the cv::imwrite() function. However, for debugging purposes it's much more convenient to see the actual values. You can do this using the << operator of Mat. Be aware that this only works for two dimensional matrices.
Although Mat works really well as an image container, it is also a general matrix class. Therefore, it is possible to create and manipulate multidimensional matrices. You can create a Mat object in multiple ways:
cv::Mat::Mat Constructor
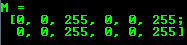
For two dimensional and multichannel images we first define their size: row and column count wise.
Then we need to specify the data type to use for storing the elements and the number of channels per matrix point. To do this we have multiple definitions constructed according to the following convention:
For instance, CV_8UC3 means we use unsigned char types that are 8 bit long and each pixel has three of these to form the three channels. This are predefined for up to four channel numbers. The cv::Scalar is four element short vector. Specify this and you can initialize all matrix points with a custom value. If you need more you can create the type with the upper macro, setting the channel number in parenthesis as you can see below.
Use C/C++ arrays and initialize via constructor
The upper example shows how to create a matrix with more than two dimensions. Specify its dimension, then pass a pointer containing the size for each dimension and the rest remains the same.
cv::Mat::create function:
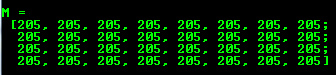
You cannot initialize the matrix values with this construction. It will only reallocate its matrix data memory if the new size will not fit into the old one.
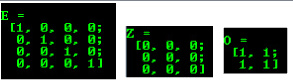
MATLAB style initializer: cv::Mat::zeros , cv::Mat::ones , cv::Mat::eye . Specify size and data type to use:
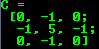
For small matrices you may use comma separated initializers:
Create a new header for an existing Mat object and cv::Mat::clone or cv::Mat::copyTo it.
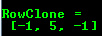
In the above examples you could see the default formatting option. OpenCV, however, allows you to format your matrix output:
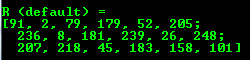
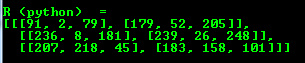
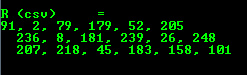

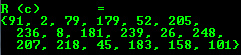
OpenCV offers support for output of other common OpenCV data structures too via the << operator:




Most of the samples here have been included in a small console application. You can download it from here or in the core section of the cpp samples.
You can also find a quick video demonstration of this on YouTube.
 1.8.11
1.8.11

